| Chang Liu1,2 | Haoning Wu1 | Weidi Xie1 |
| 1School of Artificial Intelligence, Shanghai Jiao Tong University, China |
| 2CMIC, Shanghai Jiao Tong University, China |
| Code [GitHub] | Paper [arXiv] | Data [HuggingFace] | Cite [BibTeX] |
Overview. KubriCount is a multi-grained counting benchmark covering five explicit semantic levels. The dataset tests whether models count the intended target set under prompts that specify identity, attribute, category, instance type, or concept-level granularity.
Open-world object counting remains brittle: despite rapid advances in vision-language models, reliably counting the objects a user intends is far from solved. A central reason is that counting granularity is often left implicit; users may refer to a specific identity, an attribute, an instance type, a category, or an abstract concept, yet most methods treat "what to count" as a single category-level matching problem.
We redefine open-world counting as multi-grained counting, where visual exemplars specify target appearance and fine-grained text specifies the intended semantic granularity across five explicit levels. To address the data bottleneck exposed by this formulation, we build KubriCount, a large-scale synthetic benchmark produced by controllable 3D synthesis, consistent image editing, and VLM-based filtering. KubriCount provides dense instance-level annotations and controlled distractors for training and multi-grained evaluation.
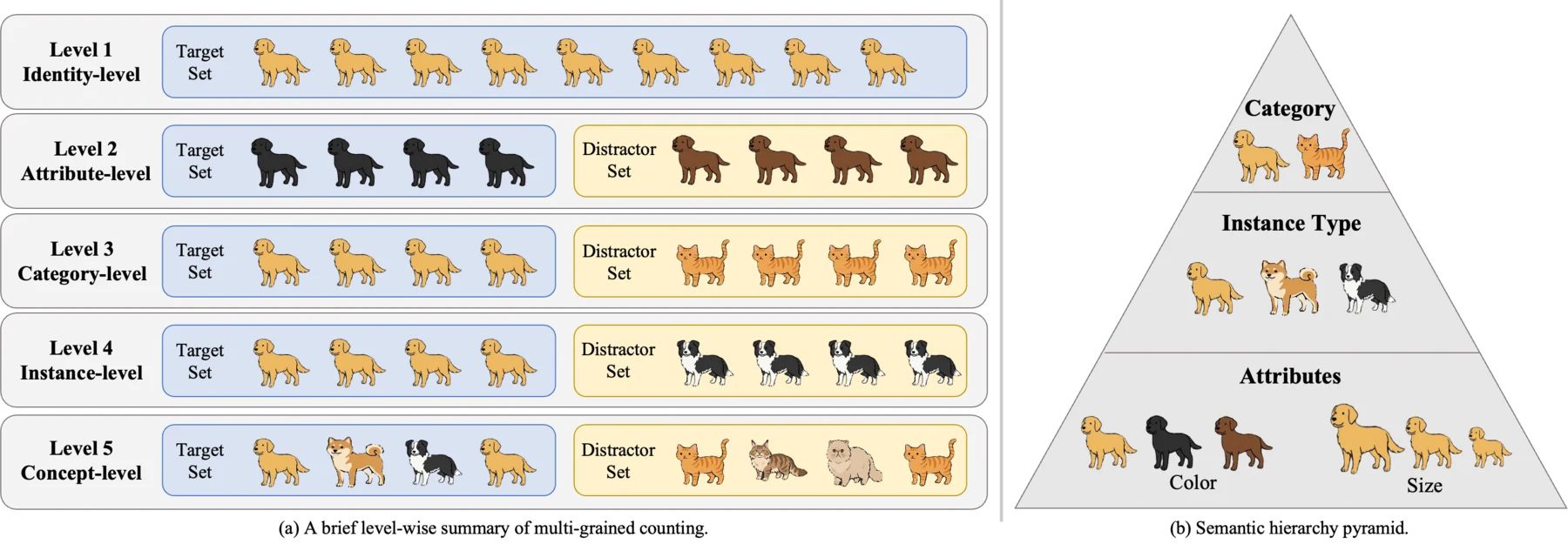
Five semantic levels. KubriCount makes counting granularity explicit by defining target and distractor sets over a semantic hierarchy: category, instance type, and attributes such as size and color.
L1: Identity-level L2: Attribute-level L3: Category-level L4: Instance-level L5: Concept-level
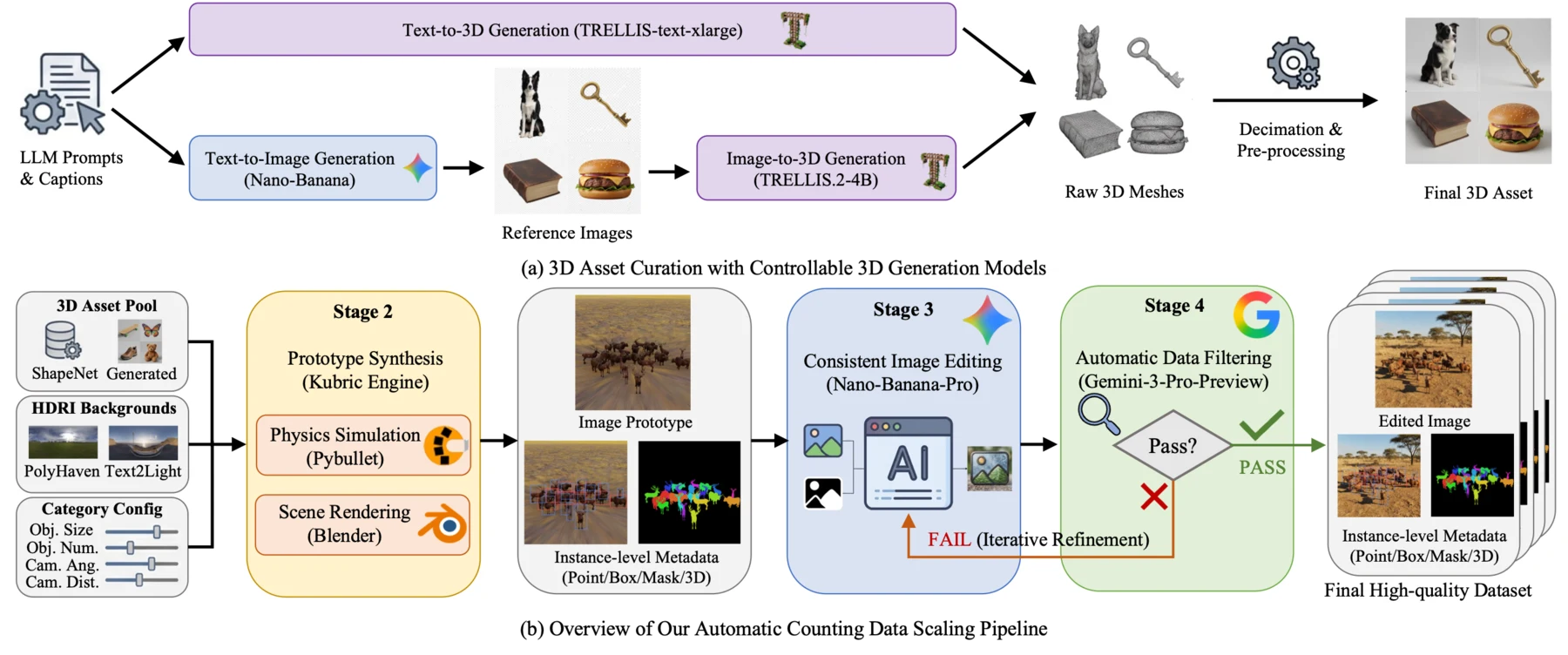
Pipeline. We curate and generate 3D assets, synthesize labeled prototypes with Kubric, apply mask-conditioned consistent image editing to improve realism, and use VLM-based filtering with an edit-filter loop to ensure label consistency.
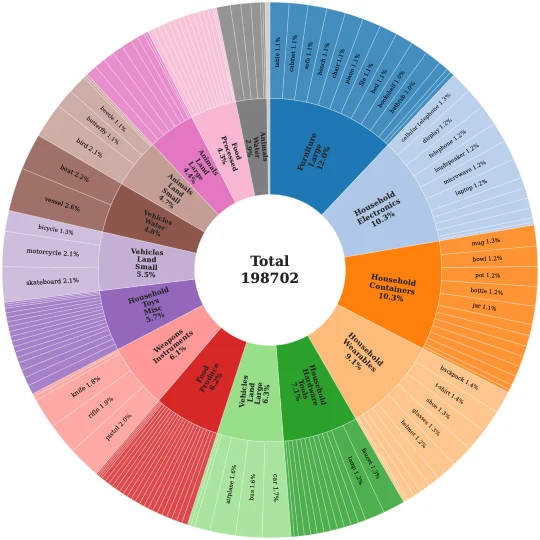
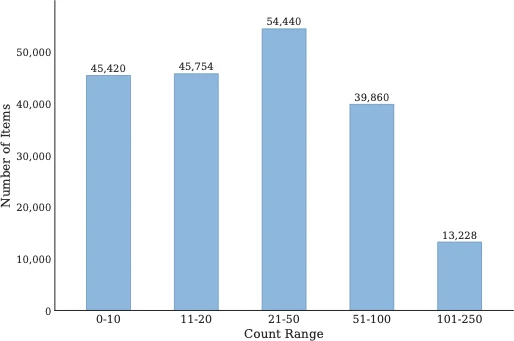
KubriCount statistics. The dataset contains 110,507 images, 157 categories, approximately 7.3M annotated objects, and up to 250 objects per image. It provides counts, center points, 2D/3D boxes, masks, and metadata for multi-grained evaluation.
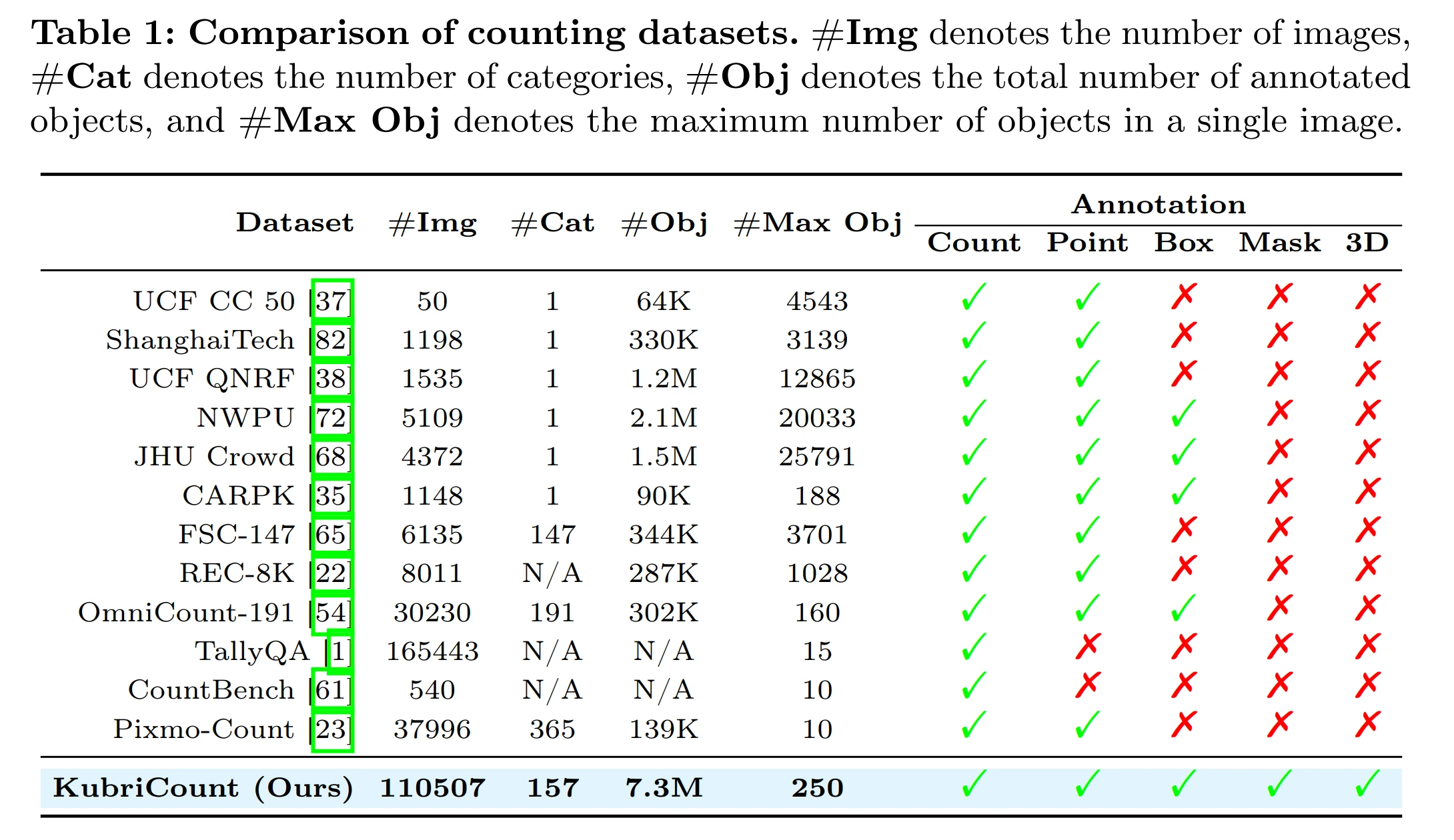
Comparison with existing counting datasets. KubriCount provides dense count, point, box, mask, and 3D annotations at substantially larger annotated-instance scale than prior visual counting benchmarks.
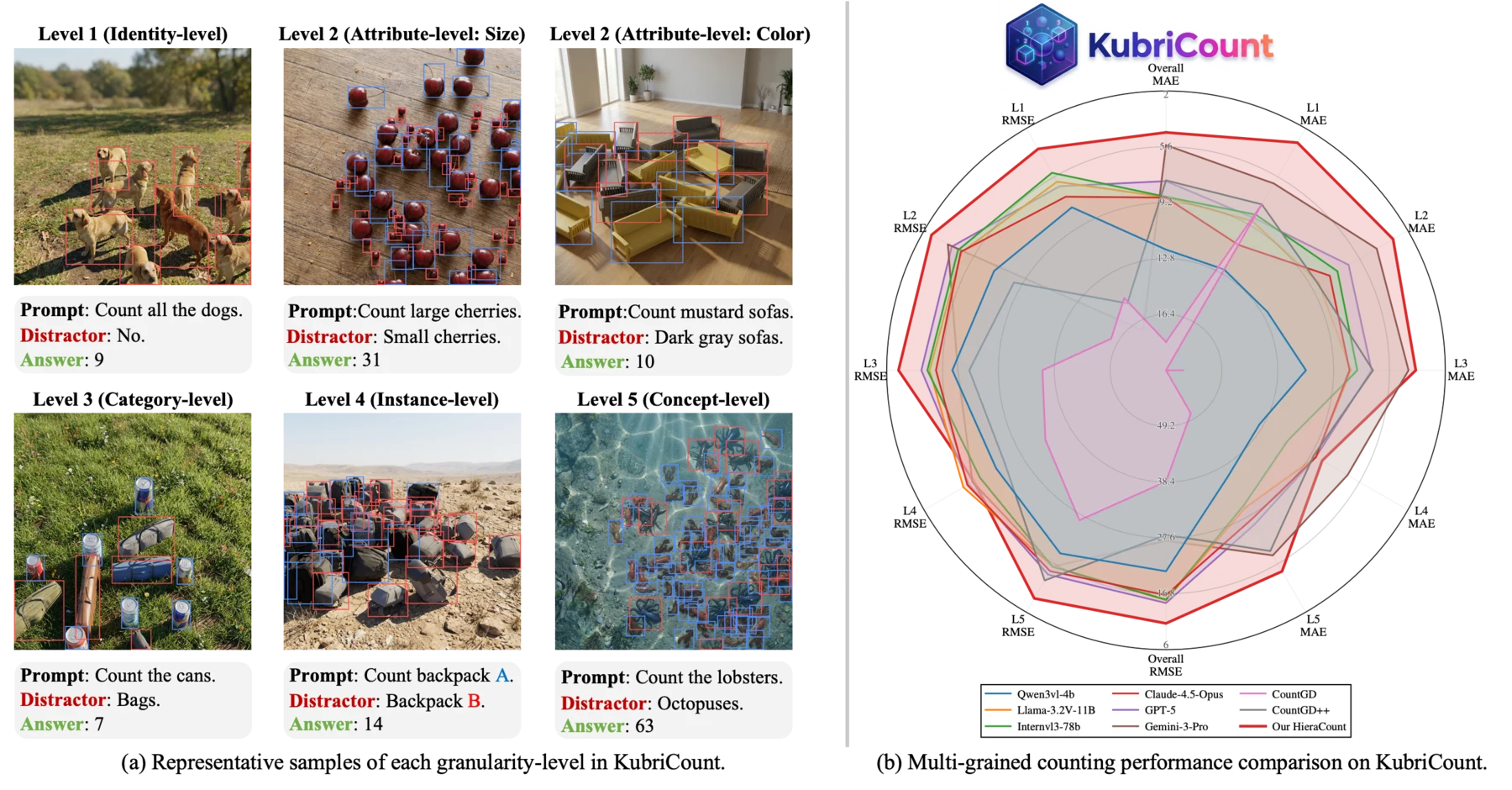
The following examples visualize each granularity level in KubriCount, including the rendered scene, target/distractor specification, and corresponding annotations.
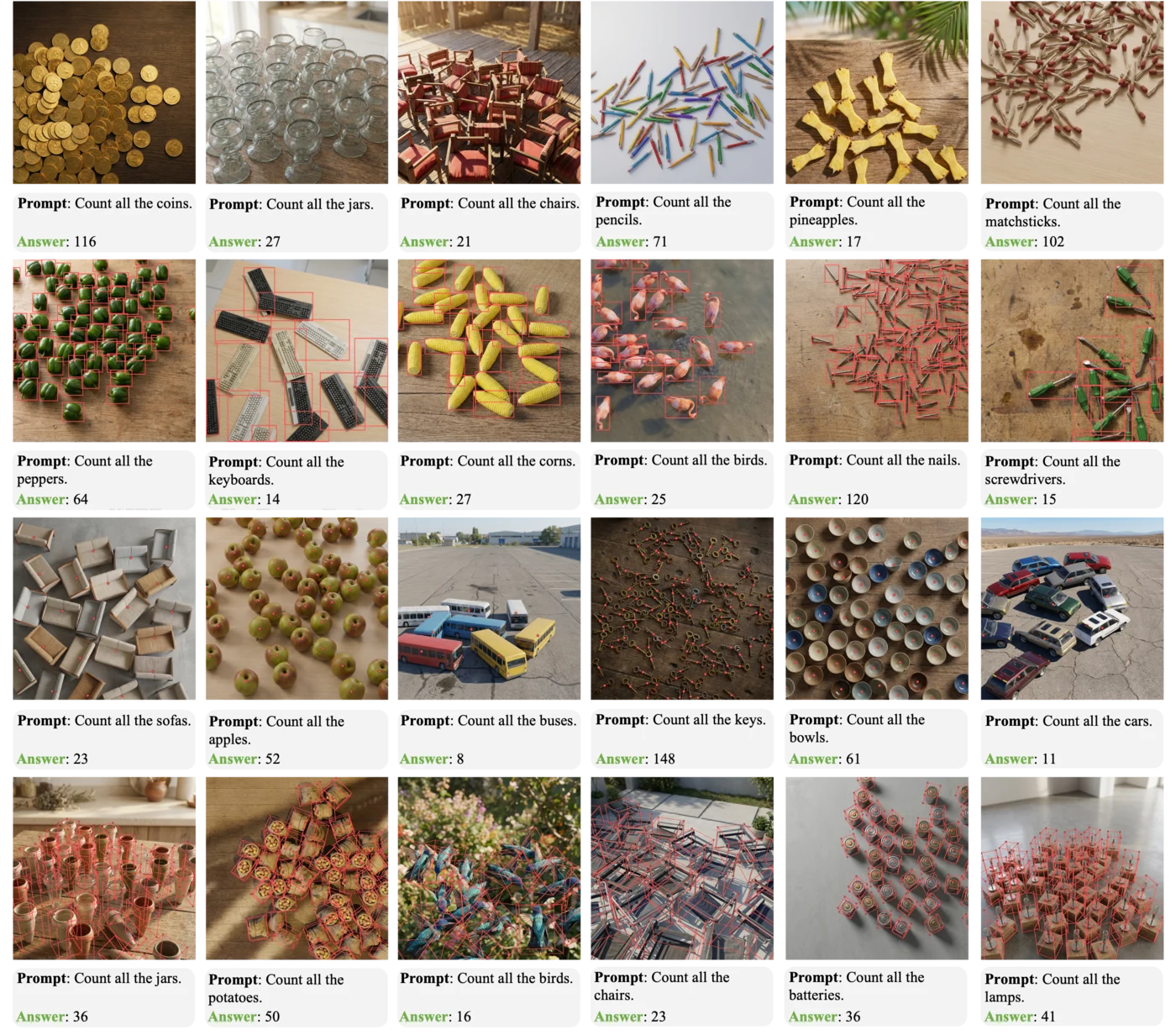
Level 1. Identity-level counting.

Level 2. Attribute-level counting by size.
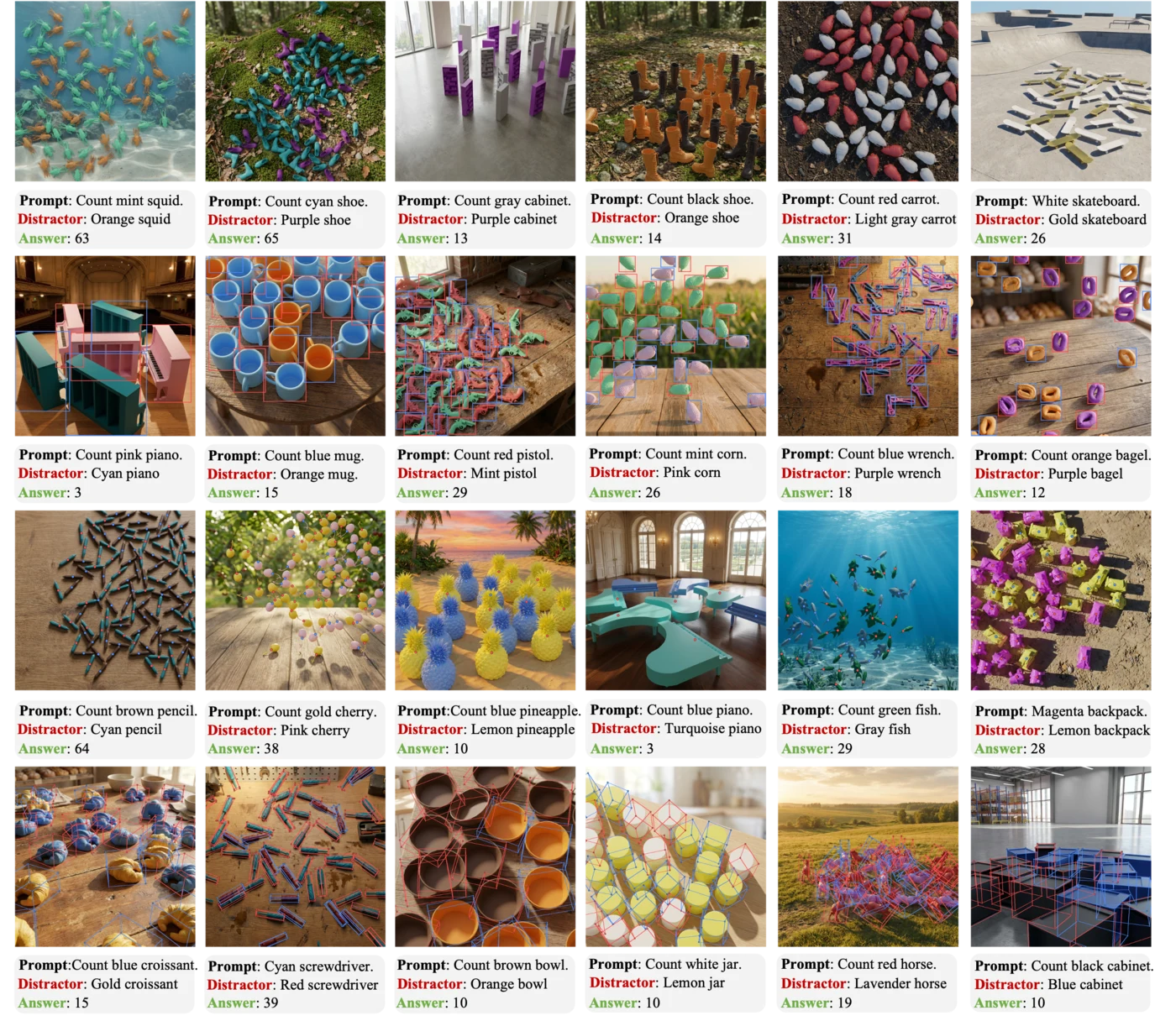
Level 2. Attribute-level counting by color.
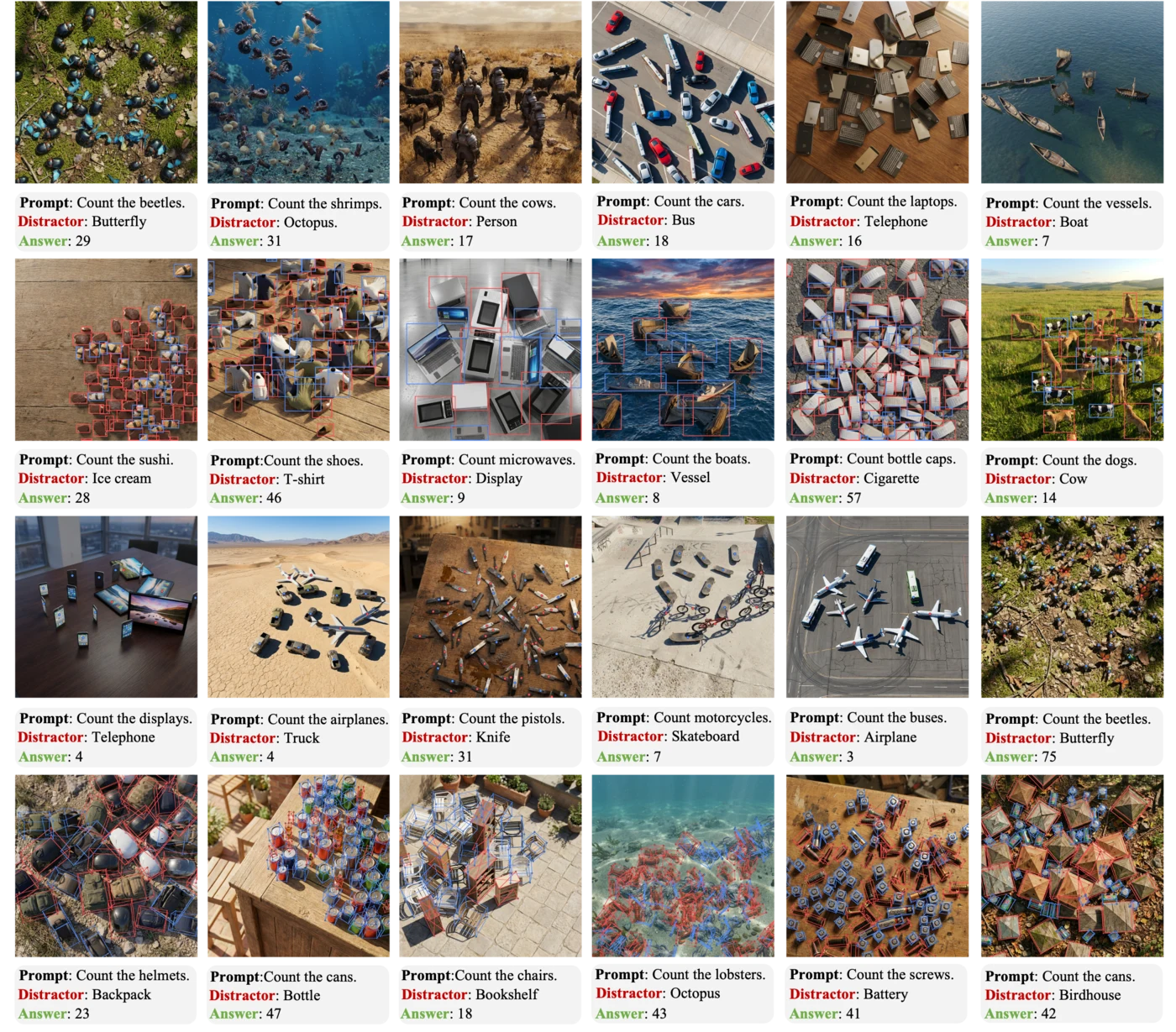
Level 3. Category-level counting.

Level 4. Instance-level counting.

Level 5. Concept-level counting.
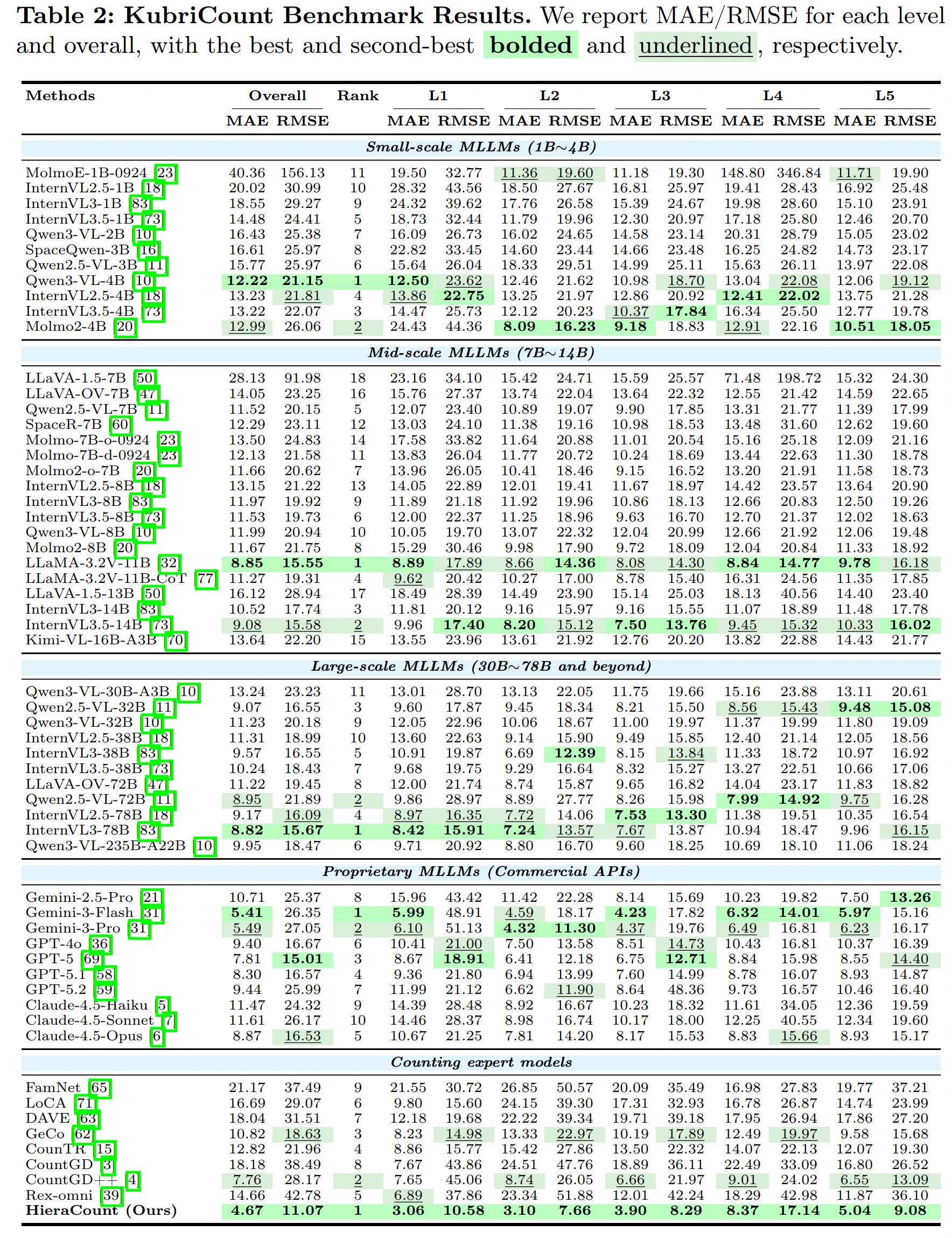
KubriCount benchmark results. We evaluate representative multimodal large language models and specialist counting models across all five granularity levels. HieraCount achieves strong multi-grained counting performance under positive-only prompting.
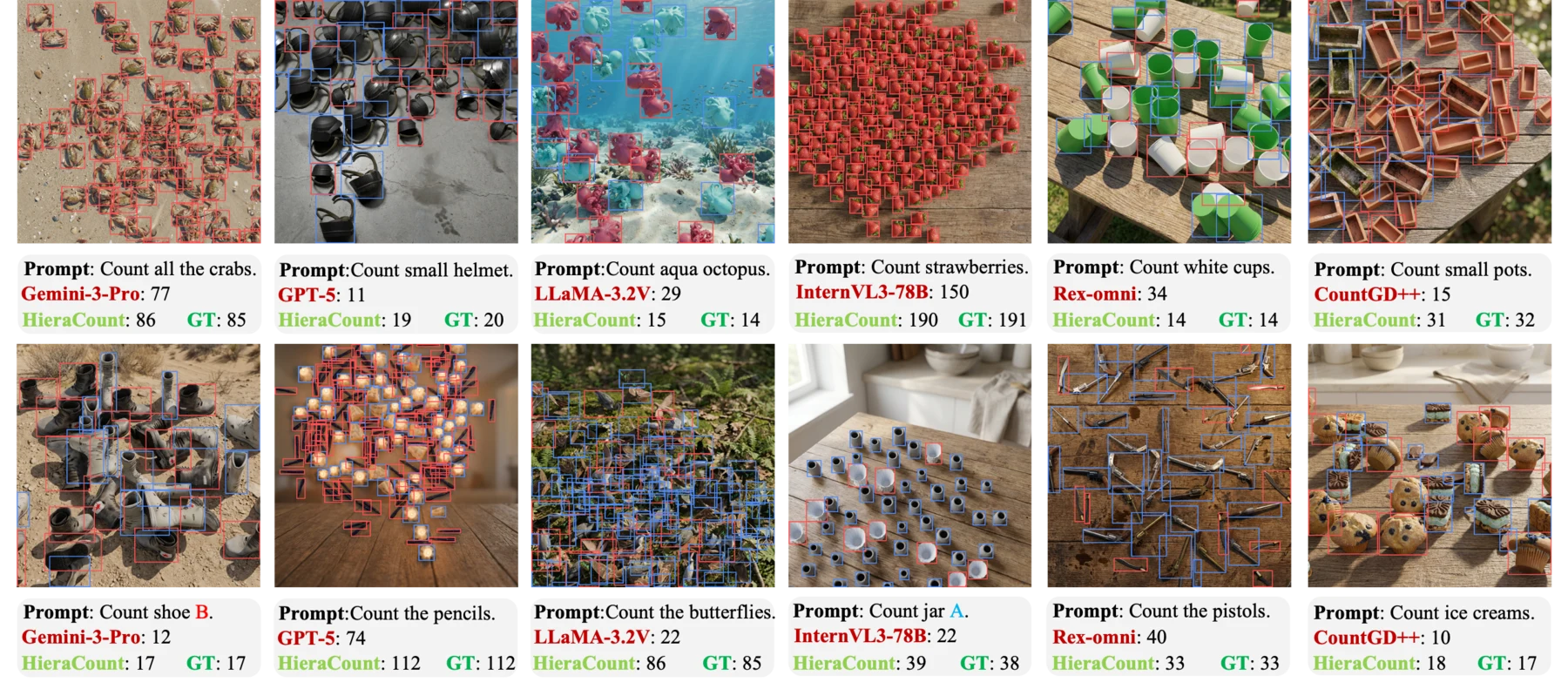
Qualitative examples. Representative cases contrast prior models with HieraCount under the same multi-grained prompts. These examples highlight improved prompt following on challenging attribute-, category-, and instance-sensitive queries.
Dataset. The KubriCount dataset is available at Hugging Face. The released dataset can be used directly without running the generation pipeline.
Paper. The paper is available on arXiv.
Code. The data generation code is available on GitHub.
If you find this project useful, please cite:
@article{liu2026count,
title={Count Anything at Any Granularity},
author={Liu, Chang and Wu, Haoning and Xie, Weidi},
journal={arXiv preprint arXiv:2605.10887},
year={2026}
}This project builds on the excellent Kubric data generation framework. We thank the Kubric authors and contributors for making their rendering and simulation infrastructure publicly available. This page follows the style of common academic project pages.
Based on a template by Phillip Isola and Richard Zhang.